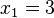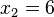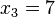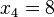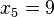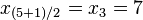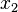Para controlar los errores aleatorios, además del cálculo de
intervalos de confianza, contamos con una segunda herramienta en el proceso de
inferencia estadística: los test o contrastes de hipótesis de manera que con los
resultados obtengamos podemos rechazar o no la hipótesis nula, es decir, si hay
relación o no entre las variables.
Con los intervalos nos hacemos una idea de un parámetro de
una población dado un par de números entre los que confiamos que esté el valor
desconocido.
Con los contrastes (test) de hipótesis la estrategia es la
siguiente:
Establecemos a "priori" una hipótesis cerca del
valor del parámetro.
Realizamos la recogida de datos.
Analizamos la coherencia de entre la hipótesis
previa y los datos obtenidos.
Sean cuales sean los deseos de los investigadores, el test
de hipótesis siempre va a contrastar la hipótesis nula (la que establece igualdad
entre los grupos a comparar, o lo que es lo mismo, la que no establece relación
entre las variables de estudio).
No permitiendo la manipulación de los datos, a
no ser que el investigador se invente los resultados.
El Test de hipótesis analiza las diferencias que existen
entre los grupos, mientras más diferencias haya, más relación causa efecto, más
se apoya la hipótesis alternativa y más me alejo de la hipótesis nula.
TIPOS DE ANÁLISIS ESTADÍSTICOS SEGÚN EL TIPO DE VARIABLES IMPLICADAS EN EL ESTUDIO:
Dependiendo del tipo de variable, vamos a realizar un tipo de test u otro:
Chi cuadrado: dos variables cuantitativas.
T.student: variable cualitativa dicotómica VS variable cuantitativa.
ANOVA: variable cualitativa policotómica VS variable cuantitativa.
Regreción lineal: dos variables cuantitativas.
ERRORES DE HIPÓTESIS.
El test de hipótesis mide la probabilidad de error que cometo sin rechazo la hipótesis nula.
Con una misma muestra podemos aceptar o rechazar la hipótesis nula. Todo depende de un error, al que llamamos alfa.
El error alfa es la probabilidad de equivocarnos al rechazar la hipótesis nula.
El error alfa más pequeño al que podemos rechazar H0 es el error p.
Habitualmente rechazamos H0 para un nivel alfa máximo del 5% (p<0'05). Por encima del 5%, aceptamos la hipótesis nula.
Es lo que llamamos "significación estadística".
TIPOS DE ERRORES EN EL TEST DE HIPÓTESIS
El error más importante para nosotros es el tipo alfa. Aceptamos equivocarnos hasta un 5%.
TEST CHI CUADRADO
Nuestra Chi cuadrado es de 17'3. Observamos en la tabla adjunta cual es el valor de Chi cuadrado, cuando p=0'05, y el grado de libertad es igual a 3.
Como podemos observar el valor de t = 7'815, teniendo en cuenta que nuesta t = 17'3, rechazamos la hipótesis nula.
Esto quiere decir que hay varía la notas de religión según sea un centro u otro.
TEST DE STUDENT
Una vez que hemos calculado el valor de t, nos fijaremos en la tabla que adjuntaremos a continuación, para el valor que tendra t, cuando p = 0'05 y cuando tenemos un grado de libertad de 25.
Como observamos el valor de t= 1'708.
Teniendo en cuenta que nuestra t= 1'55, y la de la tabla t = 1'708, aceptamos la hipótesis nula.
Eso quiere decir que existen diferencias significativas en las edades medias de las gestantes. REGRECIÓN LINEAL
Cuando planteamos un estudio en el ámbito sanitario para establecer
relaciones entre variables, nuestro interés no suele estar exclusivamente
en los pacientes concretos a los que hemos tenido acceso, sino más bien en
todos los pacientes similares a estos.
Tenemos que conocer una serie de conceptos:
Población de estudio: Es el
conjunto de pacientes sobre los que queremos estudiar la cuestión.
Muestra: Es el conjunto de individuos concretos que
participan en el estudio.
Tamaño muestral: Es el número de
individuos de la muestra.
Inferencia estadística: Es el conjunto de
procedimientos estadísticos que permiten pasar de os particular, la
muestra, a lo general, la población.
Técnicas de muestreo: Es el conjunto de
procedimientos que permiten elegir muestras de tal forma que éstas
reflejen las características de la población, sirve para evitar los
sesgos.
Es
importante considerar, que siempre que trabajemos con muestras, aunque sean
representativas, hay que asumir un cierto error.
Si la muestra se elige por un
procedimiento de azar, se puede evaluar ese error. La técnica de muestreo en
ese caso se denomina muestreo probabilistico o aleatorio, mientras
que el error asociado a esa muestra elegida al azar se llama error
aleatorio.
Sin embargo, en los estudios
probabilísticos, no podemos evaluar el error aleatorio, sin embargo podemos
evaluarlo gracias a las leyes de la probabilidad.
Cuanto mayor sea el tamaño de la
muestra, favorezco la reducción del error aleatorio por probabilidad.
PROCESO DE
LA INFERENCIA ESTADÍSTICA
Tenemos una
población de estudio, y la medida que queremos obtener se llama parámetro. Es
decir el parámetro es un número que resume la gran cantidad de datos que pueden
derivarse del estudio de una variable estadística.
Realizamos
una selección aleatoria, y obtenemos una muestra, y la medida de la variable de
estudio obtenida en la muestra, se denomina estimador.
El proceso
por el que a partir del estimador, me aproximo al parámetro se denomina INFERENCIA.
ERROR ESTÁNDAR
El error
estándar es la medida que trata de captar la variabilidad de los
valores del estimador. El error estándar de cualquier estimador mide el grado
de variabilidad en los valores del estimador en las distintas muestra de un
determinado tamaño que pudiésemos tomar de una población.
Es
importante saber que cuanto más pequeño es el error estándar de un estimador,
más fiabilidad tendrá el valor de una muestra determinada.
¿Cómo
calculamos el error estándar?
Va a
depender de cada estimador:
Error estándar para una media:
Error estándar para una
proporción:
De ambas fórmulas se deduce que,mientras mayor sea el tamaño de una
muestra, menor será el error estándar.
TEOREMA CENTRAL DEL LÍMITE
Para estimadores que pueden ser expresados como suma de valores muestrales,
la distribución de sus valores sigue una distribución normal con
medida de la población y desviación típica igual al error estándar del
estimador de que se trate.
Si sigue una distribución normal,sigue los principios básicos de ésta:
INTERVALO DE CONFIANZA
Se trata de conocer el parámetro en una población midiendo el
error que tiene que ver con el azar (error aleatorio).
Se trata de un par de números tales que, con un nivel de confianza
determinados, podamos asegurar que el valor del parámetro es mayor o menos que
ambos números.
Se calcula considerando que el estimador muestral sigue una distribución
normal como establece la teoría central del límite.
A continuación vamos a realizar un problema, explicativo:
Problema: Estamos interesados en conocer el consumo diario medio de cigarrillos entre los alumnos de un centro de Bachillerato de nuestra localidad. Seleccionada una muestra aleatoria de 100 alumnos se observó que fumaban una media de 8 cigarrillos diarios. Si admitimos que la varianza de dicho consumo es de 16 cigarrillos en el colectivo total, estime dicho medio con un nivel de confianza del 95%.
DATOS:
n= 100 alumnos.
ⴟ= 8 cigarrillos.
S2= 16 cigarrillos.
Z= 1'96, ya que el nivel de confianza es del 95% (ya que el problema sigue una distribución normal).
Tendremos que aplicar la fórmula adecuada, para determinar el error estándar de una media.
Por lo tanto el resultado sería:
IC = 99% [6'9-9'9]
IC=95% [7'22-8'78]
A continuación pondremos otro ejemplo, en este caso un tipo de error estándar para una proporción.
Problema: Tomada al azar una muestra de 120 estudiantes de una universidad se encontró que 54 de ellos hablaba inglés. Halle con un nivel de confianza del 95% con un intervalo de confianza para estimar la proporción de estudiantes que hablan el idioma inglés entre los estudiantes de esa Universidad.
MUESTREO PROBABILÍSTICO
Todos y cada
uno de los elementos tienen la misma probabilidad de ser elegidos.
Es el método que consiste en
extraer una parte (o muestra) de una población o universo, de tal forma que
todas las muestras posibles de tamaño fijo, tengan la misma posibilidad de ser
seleccionados.
Aleatorio Simple:Se caracteriza porque cada unidad
tiene la probabilidad equitativa de ser incluida en la muestra:
De sorteo o rifa: Asignamos un nº a
cada miembro de la población, calculamos el tamaño muestral y seleccionamos
aleatoriamente ese nº. este tipo de método no es fácil cuando la población es
muy grande, pasando a usar el sistema que continua.
Tabla de números aleatorios: más
económico y requiere menor tiempo. Se hace cuando disponemos de una lista
informatizada en una base de datos de la población de estudio.
Aleatorio Sistemático.
Similar al aleatorio simple, en donde
cada unidad del universo tiene la misma probabilidad de ser seleccionada.
Ejemplo: si
N:500 (población) y n:100 (personas que queremos en la muestra N/n=5
5
será el intervalo para la selección de cada unidad muestral. Si tengo las personas por número seria así: saco
un número aleatorio de la población y a partir de ahí cada 5 elijo al sujeto de
estudio. Si saco el 320 a partir de 325, 330, 335... Hasta llegar a 100. Si
termino la lista y no he llegado al 100, vuelvo a empezar de nuevo, pero
siempre con el intervalo que me ha salido.
Estratificado:
Se caracteriza por la subdivisión de
la población de estudio en subgrupos o estratos, debido a que las variables
principales que deben someterse a estudio presentan cierta variabilidad o
distribución conocida que puede afectar a los resultados. Si quiero hacer un
estudio sobre cifras de presión arterial, si la población de estudio el 25% son
menores de 15 años, el 50% entre 15-65 años y el 25% mayores de 65. Si la
muestra que necesito es de 200 personas. Seleccionare aleatoriamente siguiendo
el procedimiento anterior 100 personas de entre 15-65 años, 50 menores de 15
años, y 50 mayores de 65. Se usa
principalmente por motivos de edad y sexo.
Conglomerado.
Se usa cuando no se dispone de una
lista detallada y enumerada de cada una de las unidades que conforman el
universo y resulta muy complejo elaborarla. En la selección de la muestra en
lugar de escogerse cada unidad se toman los subgrupos o conjuntos de unidades conglomerados. Por ejemplo, quiero
hacer un estudio de Andalucía (poblaciones amplias sobre las que se usa este
método), calculo el tamaño muestral, pero si hago un muestreo aleatorio me
puede salir cada sujeto en un pueblo distinto de la población andaluza, para
evitarlo se seleccionan un grupo de municipios y dentro de ese municipio se
hacen muestreo aleatorio simple.
En este tipo de muestreo el
investigador no conoce la distribución de la variable.
Las inferencias que se hacen en una
muestra conglomerada no son tan confiable como las que se obtienen en un estudio
hecho por muestreo aleatorio, excluyendo directamente grandes municipios. El
municipio se elige por estratificación a su vez.
MUESTREO NO PROBABILÍSTICO
No
se sigue el proceso aleatorio.
No
puede considerarse que la muestra sea representativa de una población.
Se
caracteriza porque el investigador selecciona la muestra siguiendo algunos
criterios identificados para los fines del estudio que realiza.
Por
conveniencia o intencional: en el que el investigador decide, según sus
objetivos, los elementos que integraran la muestra, considerando las unidades
“típicas” de la población que desea conocer.
-Tipos:
Por cuotas: en el que el investigador selecciona
la muestra considerando algunos fenómenos o variables a estudiar, como: Sexo,
raza, religión, etc.
Accidental: consiste en utilizar para el estudio
las personas disponibles en un momento dado, según lo que interesa estudiar. De
las tres es la más deficiente.
Por conveniencia o intencional. En el que el investigado, decide
según sus objetivos, loe elementos que integraran la muestra, considerando las
unidades “típicas” de la población que se desea conocer.
TAMAÑO DE LA MUESTRA.
Por últimos explicaremos a través de un vídeo tutorial, como calcular el tamaño muestral:
En el día de hoy, intentaremos explicar las medidas de tendencia central, posición y dispersión.
Es importante saber antes de empezar, que dichas medidas solo son aplicables a variables cuantitativas.
Dentro de las cuales existen dos tipos distintos: Continuas y discretas, que fueron explicadas detalladamente en la entrada del tema anterior (Tema 7).
Existen tres grandes tipos de medidas estadísticas:
Medidas de Tendencia central: nos indican en torno a qué valor (centro) se distribuyen los datos.
Medidas de posición: dividen un conjunto de datos en grupos con el mismo número de individuos. Para calcular las medidas de posición es necesario que los datos estén ordenados de menor a mayor.
Medidas de dispersión o variabilidad: da información acerca de la heterogeneidad de nuestras observaciones.
MEDIDAS DE TENDENCIA CENTRAL.
Encontramos:
Media aritmética o media (x): Es la suma de todos los valores de la variable observada entre el total de observaciones.
Por ejemplo: Si queremos calcular la nota media de una clases de 10 sujetos, donde las notas son: 5, 7, 8, 9, 10, 4, 4, 8, 5 y 4'5.
Sumamos todas las notas de clases y la dividimos entre el número de notas, es decir:
5+7+8+9+10+4+4+8+5+4.5 / 10;
64'5 / 10 = 6'45;
Por lo que 6'45 sería la media de clase.
Mediana: representa el valor de la variable de posición central en un conjunto de datos ordenados.
Si el número de observaciones es impar: el valor de la observación será justamente la observación que ocupa la posición central.
Por ejemplo: Si tenemos 5 datos, que ordenados son: , , , , => El valor central es el tercero: . Este valor, que es la mediana de ese conjunto de datos, deja dos datos por debajo (, ) y otros dos por encima de él (, ).
Si el número de observaciones es par: el valor de la mediana corresponde a la media entre los dos valores centrales, es decir, la media entre la observación n/2 y la observación (n/2)+1.
Por ejemplo: Tenemos cuatros sujetos de edades: 10, 15, 20 y 25. Cogemos a los dos sujetos centrales y hacemos la media aritmética de ambos.
15+20 / 2 = 17'5.
Moda: Es el valor con mayor frecuencia, es decir, que más veces se repite. Se puede dar que existan dos modas, en este caso se llama bimodal, o más de dos modas, en este caso se llama multimodal.
Es IMPORTANTE saber, que se puede aplicar para variables cuantitativas y variables cualitativas.
MEDIDAS DE POSICIÓN.
Encontramos:
Cuantiles: Se calculan para variables cuantitativas y, al igual que la mediana, sólo tienen en cuenta la posición de los valores de la muestra.
Los cuantiles más usados son:
Percentiles: Divide la muestra ordenada en 100 partes. Es importante saber que el p50 corresponde al valor de la mediana.
Deciles: Dividen la muestra ordenada en 10 partes.
Cuartil: Dividen la muestra ordenada en 4 partes.
El primer cuartil Q1 = Indica el valor que ocupa una posición en la serie numérica de forma que el 25% de las observaciones son menores y que el 75% son mayores.
El segundo cuartil Q2 = indica el valor que ocupa una posición en la serie numérica de forma que el 50% de las observaciones son menores y que el 50% son mayores.
El tercer cuartil Q3 = indica el valor que ocupa una posición en la serie numérica de forma que el 75% de los observaciones son menores y que el 25% son mayores.
El cuarto cuartil Q4 = indica el valor mayor que se alcanza en la serie numérica.
-Para entenderlo vamos a poner un ejercicio explicativos.
Tenemos la siguiente tabla:
-Calcularemos: cuartiles, percentiles y deciles.
CUARTILES.
Número total = n; donde n=40
Para calcular Q1= n x 25 / 100 = 10.
Una vez que hemos calculado Q1 = 10, nos fijamos en la frecuencia absoluta (Fi), y vemos donde esta el valor 10.
Donde Fi es igual a 10, en relación con Xi es igual a 4'2. Eso quiere decir que el 25% de niños pesan menos de 4'2 Kg, y el 75% restante pesa más de 4'2 Kg.
Para calcular Q2 = n x 50 / 100 = 40 x 50 / 100 = 20.
Nos fijamos en la tabla donde Fi = 20, y nos fijamos en el valor de Xi, donde es igual a 4'5.
Esto quiere decir que el 50% de los niños pesas menos de 4'5 Kg, y el 50% restante pesa más de 4'5 Kg.
El mismo procedimiento se realizará para Q3 y Q4
PERCENTILES
Supongamos que queremos calcular el percentil 30, es decir P30 (30%).
Se realiza de la siguiente manera: P30 = n x 30 / 100 = 12.
Observamos en la columna de Fi, el 12, como no hay el número exacto cogeremos el siguiente número que le sigue es decir el número Fi = 14, que se corresponde con el Xi= 4'3.
Eso significa que el 30% pesa menos de 4'3 Kg y el 70% restante pesa más de 4'3 Kg.
DECILES
Supongamos que queremos calcular el decil 1, es decir D1.
Se realiza de la siguiente manera: D1= n x 1 / 10 = 4.
Al igual que en los anteriores cálculos nos fijamos en la Fi.
En este caso cuando Fi = 6, Xi = 3'9. Eso quiere decir que el 1 de cada 10 niños pesa menos de 3'9Kg y 9 de cada 10 pesa más de 3'9Kg.
MEDIDAS DE DISPERSIÓN
La información que nos aporta las medidas de tendencia central son limitadas. A través de las medidas que se va a explicar a continuación, nos proporciona mayor información.
En este vídeo, se explica claramente:
Rango o recorrido.
Desviación media.
Varianza.
Desviación estándar.
En el siguiente vídeo adjunto se explicará: el coeficiente de variación:
DISTRIBUCIONES NORMALES.
En
estadística se llama distribución normal, distribución de Gauss o distribución
gaussiana, a una de las distribuciones de probabilidad de variable continua que
con más frecuencia aparece en fenómenos reales. Es Distribución de probabilidad
más frecuente con variables continuas, por ejemplo, altura, peso, niveles de
colesterol…
Las
distribuciones normales en un histograma aparece una especie de Campana, por
eso la campana de Gauss. Y es simétrica respecto de los valores de posición
central, es decir que la moda va a coincidir con la media y la mediana.
Media, moda, mediana.
La gráfica de su
función de densidad tiene una forma acampanada y es simétrica respecto de los
valores posición central (media, mediana y moda, que coinciden en estas
distribuciones). Es simétrica dejando la mitad de los valores
por debajo del punto máximo y la mitad de los valores por encima.
Una
distribución normal sigue estos principios básicos: si al valor de la media le
restamos y le sumamos una desviación típica, si la serie numérica siguiera una
distribución normal (como el colesterol). Dice que el 68.25% de las
observaciones se va a sumar entre los valores de la suma y la resta de la media
a una desviación típica. Estas datos varían si sumamos una, dos o tres
desviaciones típicas.
ASIMETRÍA Y CURTOSIS
La asimetría
es al lado contrario al que vemos el pico (la moda), es decir si vemos el pico
hacia la derecha la asimetría es a la izquierda, y si la moda está a la
izquierda la asimetría esta hacia la derecha.
Coeficiente de asimetría de una variable:
Grado de asimetría de la distribución
de sus datos en torno a su media, cuanto más asimétrica sea, valores más
diferentes encontraremos. Es adimensional.
Asimetrías:
Los
resultados pueden ser los siguientes:
-g1=0
(distribución simétrica; existe la misma concentración de valores a la derecha
y a la izquierda de la media).
-g1>0
(distribución asimétrica positiva; existe mayor concentración de valores a la derecha de la media que a su izquierda).
-g1<0
(distribución asimétrica negativa; existe mayor concentración de valores a la
izquierda de la media que a su derecha).
CURTOSIS O APUNTAMIENTO DE LA CURVA.
No tiene
relación con la simetría. Coeficiente de apuntamiento o curtosis de una
variable, sirve para medir el grado de concentración de los valores que toma en
torno a su media. Los datos se acumulan mucho, mientras más se acumulen, más
apuntada esta la curva.
Se elige
como referencia una variable con distribución normal, de modo que para ella el
coeficiente de curtosis es 0.
Los
resultados pueden ser los siguientes:
-g2=0
(distribución mesocúrtica o normal). Presenta un grado de concentración medio
alrededor de los valores centrales de la variable (el mismo que presenta una
distribución normal). Presentan un grado de concentración medio a los valores de la media.
-g2>0
(distribución leptocúrtica). Presenta un elevado grado de concentración
alrededor de los valores centrales de la variable.
-g2<0
(distribución platicúrtica). Presenta un reducido grado de concentración
alrededor de los valores centrales de la variable.
¿Qué es la Bioestadística?: Es la ciencia que aplica el análisis estadístico a los problemas y a los objetos de estudio de la biología.
La estadística es el conjunto de procedimientos y técnicas empleadas para recolectar, organizar y analizar datos, los cuales sirven de base para tomar decisiones en las situaciones de incertidumbre que plantean las ciencias sociales o naturales.
Podemos decir que se trata de la ciencia que estudia la variabilidad.
Las diferentes variables a estudiar, pueden tener distintas naturaleza y diferentes métodos de medición. Pongamos un ejemplo:
La presencia del dolor se puede mediar como si o no, sin embargo la glucemia basal se tendrá que medir por mg de glucosa por dl de sangre, con valores que pueden ir de 0 a 1000 mg/dl,
Como compramos son variables de diferentes naturaleza.
Para medir variables se utilizan diferentes escalas.
TIPOS DE ESCALAS.
ESCALA NOMINAL
Se trata, con variables numéricas cuyos valores representan una categoría o identifica un grupo de pertenencia. Este tipo de variables sólo nos permite establecer relaciones de igualdad/desigualdad entre los elementos de la variable.
La asignación de los valores se realiza en forma aleatoria por lo que NO cuenta con un orden lógico.
Por ejemplo:
Género:
Femenino.
Masculino.
Estado Civil:
Soltero.
Casado.
Divorciado.
Viudo.
ESCALA ORDINAL
Se trata, con variables numéricas cuyos valores representan una categoría o identifican un grupo de pertenencia contando con un orden lógico. Este tipo de variables nos permite establecer relaciones de igualdad/desigualdad y a su vez, podemos identificar si una categoría es mayor o menos que otra.
Ejemplo:
Nivel de instrucción:
Preescolar.
Bachillerato.
Superior.
Escala de opinión:
Me gusta.
No me gusta.
Tal vez.
No opino.
ESCALA DE INTERVALO
Se trata, con variables numéricas cuyos valores representan magnitudes y la distancia entre los números de su escala es igual. Con este tipo de variables podemos realizar comparaciones de igualdad/desigualdad, establecer un orden dentro de sus valores y medir la distancia existente entre cada valor de escala. Las variables de intervalo carecen de un cero absoluto, por lo que operaciones como la multiplicación y la división no son realizables.
Por ejemplo:
Temperatura de una ciudad expresada en:
Grados Cº.
Grafos Fº.
La altura de una ciudad, usando como referencia:
Altitud sobre el nivel del mar.
ESCALA DE RAZÓN
Las variables de razón poseen las mismas características de las variables de intervalo, con la diferencia que cuentan con un cero absoluto, es decir, el valor cero (0) representa la ausencia total de medida, por lo que se puede realizar cualquier operación aritmética (suma, resta, multiplicación, división) y lógica (comparación y ordenamiento).
Este tipo de variables permiten el nivel más alto de medición. Las variables altura, peso, distancia o el salario.
Por ejemplo:
Peso.
Edad.
Estatura.
Ingreso familiar.
Tiempo de realizar una tarea.
TIPOS DE VARIABLES.
VARIABLE CUALITATIVA
Las variables cualitativas son aquellas que se refieren a características o cualidades que no pueden ser medidas con números. Podemos distinguir dos tipos:
Variable cualitativa nominal: presenta modalidades no numéricas, que no admiten un criterio de orden. Por ejemplo: El estado civil, con las siguientes modalidades: soltero, casado, separado, divorciado y viudo. Dentro de ella encontramos dos:
Dicotómicas: porque tiene dos niveles o categorías. Todo lo que se responda con si o no es dicotómico. Por ejemplo: ¿está usted enfermo?
Policotómicas: Más de dos categorías.
Variable cualitativas ordinal: presenta modalidades no numéricas, en las que existen un orden. Por ejemplo: La nota de un examen.
Las categorías deben construirse con dos criterios: Exhaustividad (que todos los sujetos puedan ser clasificado en algún punto de la escala y exclusividad (solo pueden estar incluidos en una categoría).
VARIABLE CUANTITATIVAS
Las variables cuantitativas es la que se expresa mediante un número, por tanto se pueden realizar operaciones aritméticas con ella. Podemos distinguir dos tipos:
Variable cuantitativas discreta: es aquella que toma valores aislados, es decir no admite valores intermedios entre dos valores específicos. Por ejemplo: El número de hermanos de 5 amigos: 2, 1, 0, 1, 3.
Variable cuantitativa continuas: es aquella que puede tomar valores comprendidos entre dos números. Por ejemplo: La altura de los 5 amigos: 1'73, 1'77, 1'82, 1'60, 1'96.
Una variable discreta no podemos convertirla en una continua, pero al revés sí.
VARIABLES: REPRESENTACIÓN DE DATOS.
TABLAS DE FRECUENCIA
Son la imagen de los datos que muestran frecuencias en columnas las categorías de las variables en las filas.
Representan información repetitiva de forma visible y comprensible.
A continuación adjuntaremos un vídeo, donde podremos entender fácilmente, de que manera construir dichas tablas de frecuencias:
VARIABLES CONTINUAS: REPRESENTACIÓN DE DATOS.
Los datos pueden tener tantos decimales como se desee y que entre cada dos de ellos siempre puede haber otro, se llaman continuos. Al poder estar muy cerca unos de otros, no se pueden estudiar de uno en uno y se agrupan en intervalos.
Los datos se agrupan como hemos dicho en intervalos.
A continuación explicaremos como realizarlo:
La primera operación que hay que aprender es la de agrupar los datos.
Ejemplo: En un centro de salud se pretende realizar un estudio sobre cifras de la tensión arterial diastólica en un grupo de 30 pacientes que acude a consulta de enfermería en los programas de atención al paciente cardiovascular. Los enfermeros del programa midieron la tensión arterial diastólica de los 30 pacientes obteniendo las siguientes cifras en mm de mercurio:
45 45 45 60 60 60
65 71 74 78 80 80
80 85 85 87 87 87
87 87 87 95 95 95
95 100 100 106 109 120
En primer lugar calculamos el recorrido: (Re). Se calcula restando el valor más alto de los datos (Xn ) que nos aporta la tabla y el valor más bajo (X1)
Re = Xn – X1
Donde Xn = 120 y X1 = 45. Por lo que Re = 120 - 45 = 75.
En segundo lugar, calculamos el nº intervalo: cuando no se nos dice nada del número de intervalos, se obtienen calculando la raíz cuadrada del nº de datos observado.
N = 30; La raíz cuadrada de 30 = 5'47. Por lo tanto utilizaremos 5 intervalos.
Por último calcularemos la amplitud, que se calcula dividiendo el recorrido entre el nº de intervalos, por lo tanto:
75 / 5 = 15.
Una vez que hemos determinados recorrido (rango), nº de intervalo y la amplitud, podemos pasar a elaborar la tabla de frecuencia, con la información que se proporciono en el anterior apartado de esta entrada:
*También es fundamental determinar la marca de clase (mc) = diferencia intervalo / 2. Pogamos un ejemplo:
Cojamos el primer intervalo ( [45-60) ), por lo que 45 + 60 / 2 = 52'5, como podemos observar en la tabla.
¿Cómo hemos calculado en este caso la frecuencia relativa (hi)?:
Se calcula dividiendo la frecuencia absoluta entre N. Pongamos un ejemplo:
Cojamos el intervalo primero ( [45-60) ), la frecuencia absoluta (Fi) es 3 y N es 30, por lo tanto la frecuencia relativa (hi) es 3 / 30 = 0'1, como podemos observar en la tabla.
REPRESENTACIÓN GRÁFICAS.
Los gráficos son medios popularizados y a menudo lo más conveniente para presentar datos, se emplean para tener una representación visual de la totalidad de la información. Los gráficos estadísticos presenta los datos en forma de dibujo de tal modo que se pueda percibir fácilmente los hechos esenciales y compararlo con otros.
Explicaremos dos tipos de gráficos estadísticos:
Diagrama de barras.
Histograma.
DIAGRAMA DE BARRAS:
HISTOGRAMA:
La única diferencia que existe con el anterior es que se utiliza para variables continuas.
GRÁFICOS DE TRONCO Y HOJAS
Es una forma de expresar variables cuantitativas, continuas particularmente.
GRÁFICOS DE SECTORES
Se utilizan para trabajar con variables cualitativas. Para variables con pocas categorías como por ejemplo las dicotómicas.
GRÁFICOS PARA DATOS BIDIMENSIONALES
Se utilizan para variables cuantitativas.
GRÁFICOS PARA DATOS MULTIDIMENSIONALES. DIAGRMAS DE ESTRELLAS.